 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynAgent: Generalizable Cooperative Humanoid Manipulation via Solo-to-Cooperative Agent Synergy
Apr 20, 2026Controllable cooperative humanoid manipulation is a fundamental yet challenging problem for embodied intelligence, due to severe data scarcity, complexities in multi-agent coordination, and limited generalization across objects. In this paper, we present SynAgent, a unified framework that enables scalable and physically plausible cooperative manipulation by leveraging Solo-to-Cooperative Agent Synergy to transfer skills from single-agent human-object interaction to multi-agent human-object-human scenarios. To maintain semantic integrity during motion transfer, we introduce an interaction-preserving retargeting method based on an Interact Mesh constructed via Delaunay tetrahedralization, which faithfully maintains spatial relationships among humans and objects. Building upon this refined data, we propose a single-agent pretraining and adaptation paradigm that bootstraps synergistic collaborative behaviors from abundant single-human data through decentralized training and multi-agent PPO. Finally, we develop a trajectory-conditioned generative policy using a conditional VAE, trained via multi-teacher distillation from motion imitation priors to achieve stable and controllable object-level trajectory execution. Extensive experiments demonstrate that SynAgent significantly outperforms existing baselines in both cooperative imitation and trajectory-conditioned control, while generalizing across diverse object geometries. Codes and data will be available after publication. Project Page: http://yw0208.github.io/synagent
Sparsification and Reconstruction from the Perspective of Representation Geometry
May 28, 2025Sparse Autoencoders (SAEs) have emerged as a predominant tool in mechanistic interpretability, aiming to identify interpretable monosemantic features. However, how does sparse encoding organize the representations of activation vector from language models? What is the relationship between this organizational paradigm and feature disentanglement as well as reconstruction performance? To address these questions, we propose the SAEMA, which validates the stratified structure of the representation by observing the variability of the rank of the symmetric semipositive definite (SSPD) matrix corresponding to the modal tensor unfolded along the latent tensor with the level of noise added to the residual stream. To systematically investigate how sparse encoding alters representational structures, we define local and global representations, demonstrating that they amplify inter-feature distinctions by merging similar semantic features and introducing additional dimensionality. Furthermore, we intervene the global representation from an optimization perspective, proving a significant causal relationship between their separability and the reconstruction performance. This study explains the principles of sparsity from the perspective of representational geometry and demonstrates the impact of changes in representational structure on reconstruction performance. Particularly emphasizes the necessity of understanding representations and incorporating representational constraints, providing empirical references for developing new interpretable tools and improving SAEs. The code is available at \hyperlink{https://github.com/wenjie1835/SAERepGeo}{https://github.com/wenjie1835/SAERepGeo}.
Structured Context Enhancement Network for Mouse Pose Estimation
Dec 01, 2020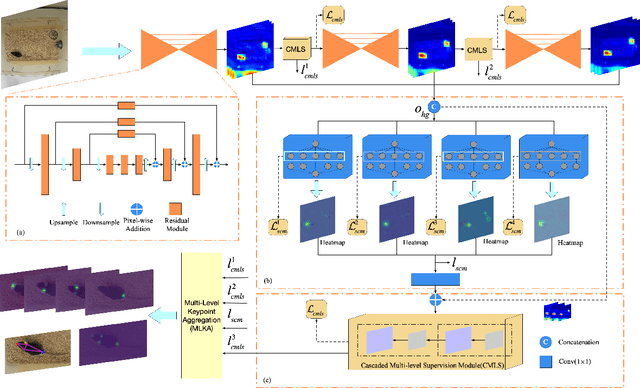
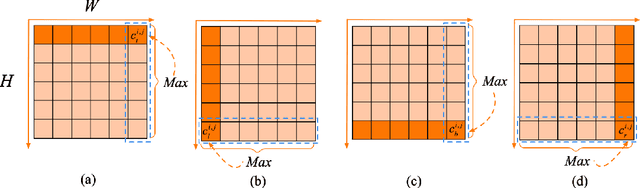
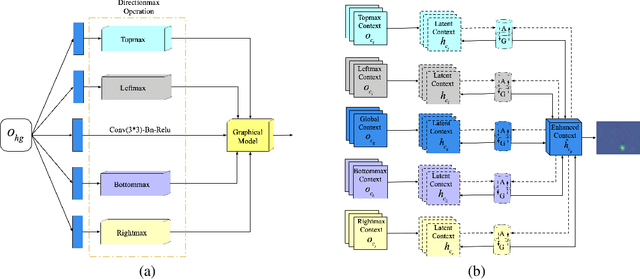
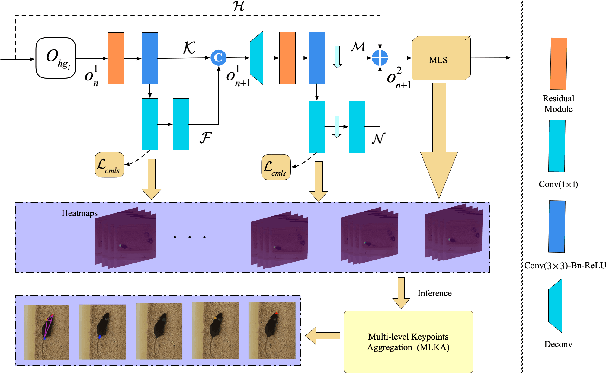
Automated analysis of mouse behaviours is crucial for many applications in neuroscience. However, quantifying mouse behaviours from videos or images remains a challenging problem, where pose estimation plays an important role in describing mouse behaviours. Although deep learning based methods have made promising advances in mouse or other animal pose estimation, they cannot properly handle complicated scenarios (e.g., occlusions, invisible keypoints, and abnormal poses). Particularly, since mouse body is highly deformable, it is a big challenge to accurately locate different keypoints on the mouse body. In this paper, we propose a novel hourglass network based model, namely Graphical Model based Structured Context Enhancement Network (GM-SCENet) where two effective modules, i.e., Structured Context Mixer (SCM) and Cascaded Multi-Level Supervision module (CMLS) are designed. The SCM can adaptively learn and enhance the proposed structured context information of each mouse part by a novel graphical model with close consideration on the difference between body parts. Then, the CMLS module is designed to jointly train the proposed SCM and the hourglass network by generating multi-level information, which increases the robustness of the whole network. Based on the multi-level predictions from the SCM and the CMLS module, we also propose an inference method to enhance the localization results. Finally, we evaluate our proposed approach against several baselines...
A Novel Deep Neural Network Based Approach for Sparse Code Multiple Access
Jun 19, 2019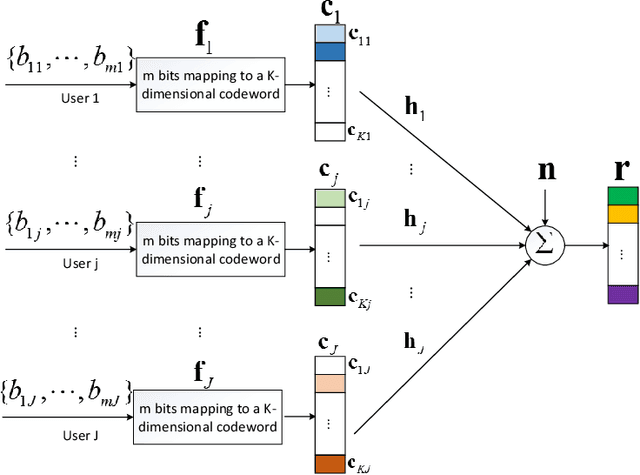

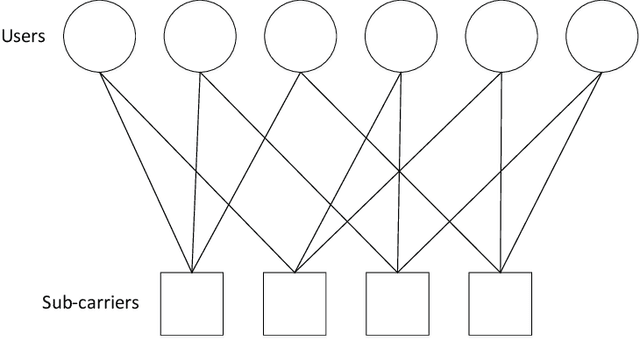

Sparse code multiple access (SCMA) has been one of non-orthogonal multiple access (NOMA) schemes aiming to support high spectral efficiency and ubiquitous access requirements for 5G wireless communication networks. Conventional SCMA approaches are confronting remarkable challenges in designing low complexity high accuracy decoding algorithm and constructing optimum codebooks. Fortunately, the recent spotlighted deep learning technologies are of significant potentials in solving many communication engineering problems. Inspired by this, we explore approaches to improve SCMA performances with the help of deep learning methods. We propose and train a deep neural network (DNN) called DL-SCMA to learn to decode SCMA modulated signals corrupted by additive white Gaussian noise (AWGN). Putting encoding and decoding together, an autoencoder called AE-SCMA is established and trained to generate optimal SCMA codewords and reconstruct original bits. Furthermore, by manipulating the mapping vectors, an autoencoder is able to generalize SCMA, thus a dense code multiple access (DCMA) scheme is proposed. Simulations show that the DNN SCMA decoder significantly outperforms the conventional message passing algorithm (MPA) in terms of bit error rate (BER), symbol error rate (SER) and computational complexity, and AE-SCMA also demonstrates better performances via constructing better SCMA codebooks. The performance of deep learning aided DCMA is superior to the SCMA.